※ 본 포스팅은 펭귄브로의 3분 딥러닝 파이토치맛에 기재된 내용과 사진을 기반으로 포스팅하였습니다.

예제 소스 : https://github.com/keon/3-min-pytorch
GitHub - keon/3-min-pytorch: <펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드
<펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드. Contribute to keon/3-min-pytorch development by creating an account on GitHub.
github.com
6장은 입력값만으로 학습하는 오토인코더에 대한 내용으로 사람의 지도 없이 학습한다.
오토인코더(autoencoder)는 레이블이 없이 특징을 추출하는 신경망이다.
6.1 오토인코더 기초
데이터 형태와 상관없이 사람이 레이블링 하여 직접 정답을 알려주면 머신러닝 모델은 매우 효율적으로 학습할 수 있다. 입력과 출력의 관계만 설명할 수 있으면 되기 때문이다. 하지만 데이터셋에 정답이 포함되지 않은 경우에는 이야기가 달라진다. 예를 들어 외국어를 배울 때, 한 글자도 모르는 상태에서 원서만으로 배우라고 하면 어려운 것과 비슷한 느낌이다. 그럼에도 주어진 데이터만으로 패턴을 찾는 비지도 학습은 흥미로운 주제이다. 세상에 존재하고 계속 생산되는 데이터의 대부분은 정답이 없기 때문이다. 인공지능이 실생활과 서비스에서 진정한 확장성을 가지려면 비지도 학습과 준지도 학습의 발전이 뒷받침되어야 할 것이다.

준지도 학습은 기계 학습의 한 범주로 목표값이 표시된 데이터와 표시되지 않은 데이터를 모두 훈련에 사용하는 것을 말한다. 레이블이 부족한 데이터를 학습하는 방법을 준지도 학습이라고 한다.
비지도 학습은 기계 학습의 일종으로, 데이터가 어떻게 구성되었는지를 알아내는 문제의 범주에 속한다. 입력값에 대한 목표치가 주어지지 않는다. 다시 말해, 지도학습과는 다르게 정답이 '없는' 데이터로 학습한다. 정답이 없는 데이터로부터 군집 분석, 데이터 표현, 차원 감소 등을 배울 수 있다. 정답이 없기 때문에 사람이 원하는 결과를 도출해내기 어렵다.
우리가 지금까지 했던 학습은 지도 학습으로 단순히 말해 입력 x와 정답 y사이를 잇는 관계를 찾는 것이다. 정답이 있으면 오차를 측정할 수 있기 때문에 현재 예측값이 얼마나 틀렸는지도 명확하고 오찻값을 구하기도 쉽다.
하지만, 정답이 없는 비지도 학습에서는 오찻값을 구하기가 모호하다. 그래서 '정답이 있으면 오찻값을 구할 수 있다'라는 아이디어를 빌려 x를 입력받아 x를 예측하고, 신경망에 의미 있는 정보가 쌓이도록 설계된 신경망이 오토인코더이다.

※매니폴드
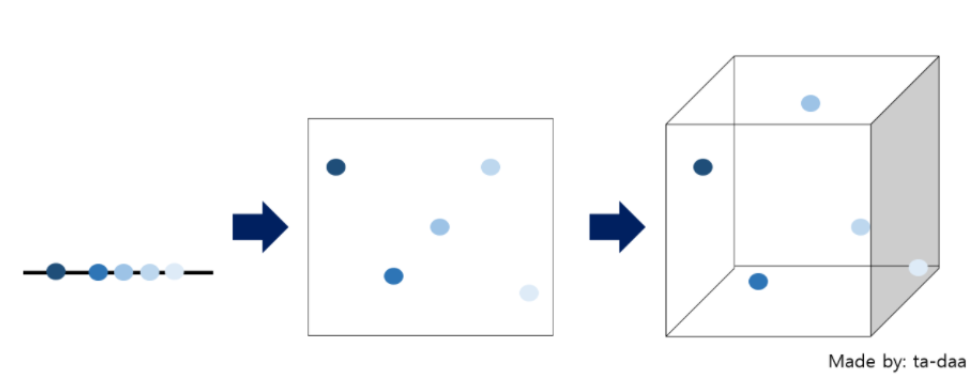
매니폴드란 고차원데이터가 있을 때 고차원 데이터를 데이터 공간에 뿌리면 샘플들을 잘 아우르는 subspace가 있을 것이라고 가정하는 것을 말한다. 다시 말해 고차원의 데이터를 저차원으로 옮길 때 데이터를 잘 설명하는 집합의 모형을 의미한다. 따라서, 고차원을 잘 표현한 저차원의 매니폴드를 통해 데이터의 중요한 특징들을 뽑아낼 수 있다.
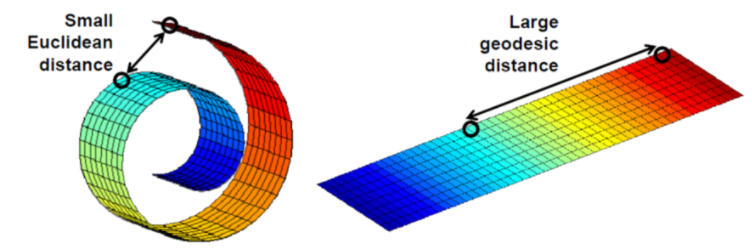
※ 차원의 저주
차원의 저주란 데이터 학습을 위해 차원이 증가하면서 학습데이터 수가 차원의 수보다 적어져 성능이 저하되는 현상을 말한다. 차원이 증가할수록 개별 차원 내 학습할 데이터 수가 적어지는 것을 말한다. 즉, 차원이 증가함에 따라 모델의 성능이 안 좋아지는 현상을 의미한다. 이러한 문제를 해결하기 위해서는 차원을 축소시키거나 많은 데이터를 사용하는 것이다. (출처 : https://datapedia.tistory.com/15)
오토인코더의 중요한 특징은 입력과 출력의 크기는 같지만, 중간으로 갈수록 신경망 차원이 줄어든다는 것이다. 이러한 구조로 인해 정보의 통로가 줄어들고 병목현상이 일어나 입력의 특징들이 '압축'되도록 학습된다. 작은 차원에 고인 압축된 표현을 잠재 변수라고 한다. 잠재 변수의 앞뒤를 구분하여 앞부분을 인코더, 뒷부분을 디코더라고 한다. 인코더는 정보를 받아 압축한다. 디코더는 압축된 표현을 풀어 입력을 복원하는 역할을 해서 붙여진 이름이다.
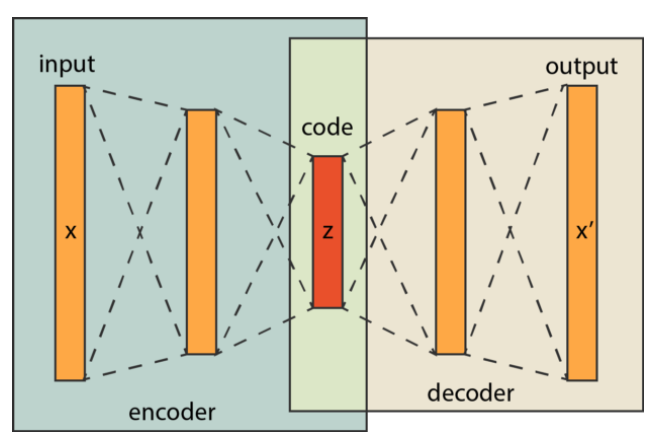
신경망이 받은 이미지를 복원하도록 학습하고 나면 잠재 변수엔 이미지의 정보가 저장된다. 낮은 차원에 높은 밀도로 표현된 데이터이므로 '의미의 압축'이 일어난다. 오토인코더는 잠재 변수에 복잡한 데이터의 의미를 담을 수 있다는 점에서 특별하다. 정보를 압축할 수 있다는 것은 결국 정보의 구성에 우선순위가 있다는 뜻이다. 이러한 맥락에서 압축이란 정보에서 덜 중요한 요소를 버리는 과정으로 정의할 수 있다. 오토인코더에서는 필연적으로 정보의 손실이 일어난다. 정보의 손실은 원본 데이터의 디테일을 잃어버린다는 뜻이기도 하지만, 중요한 정보만 남겨두는 일종의 데이터 가공이라고 볼 수도 있다.
6.3 오토인코더로 망가진 이미지 복원하기
잡음 제거 오토인코더는 2008년 몬트리올 대학에서 발표한 논문에서 처음 제안했다. 오토인코더는 일종의 '압축'을 한다. 여기서의 압축은 데이터의 특성에 우선순위를 매기고 낮은 순위의 데이터를 버린다는 뜻이다. 잡음 제거 오토인코더의 아이디어는 중요한 특징을 추출하는 오토인코더 특성을 이용하여 비교적 '덜 중요한 데이터'인 잡음을 제거하는 것이다.
이 내용을 코드로 구현할 때 코드의 구조는 기본 적인 오토인코더와 큰 차이는 없으며, 학습할 때 입력에 잡음을 더하는 방식으로 복원 능력을 강화한 것이 핵심이다. add_noise() 함수를 만들어서 더해 이미지에 무작위 잡음을 더하면 된다.


무작위 잡음을 구하고, 원래 이미지와 더해준 후, 인코더로 차원을 축소시키고 디코더로 축소시켜준 것을 다시 원래 차원으로 이미지를 복원시킨다.
잡음 제거 오토인코더를 통해 특징 추출 과정에서 '덜 중요한' 특징인 티셔츠 그림이 오토인코더에서 버려진 것을 사진(두 번째 사진)을 통해 알 수 있다.
6.4 마치며
오토인코더의 개념에 대해 배웠으며, 오토인코더가 어떻게 동작하고 어떤 결과를 도출하는지 알아 보았다. 이를 통해 오토인코더가 특징에 우선순위를 두고 덜 중요한 부분을 제거한다는 사실을 확인했다.
※ 비지도 학습, 준지도 학습 정의 출처 : https://ko.wikipedia.org/wiki/%EB%B9%84%EC%A7%80%EB%8F%84_%ED%95%99%EC%8A%B5
https://ko.wikipedia.org/wiki/%EC%A4%80%EC%A7%80%EB%8F%84_%ED%95%99%EC%8A%B5
'ML 관련 스터디' 카테고리의 다른 글
| 펭귄브로의 3분 딥러닝 파이토치맛 3장 스터디 (0) | 2023.12.13 |
|---|---|
| 펭귄브로의 3분 딥러닝 파이토치맛 4장 스터디 (0) | 2023.12.13 |
| 펭귄브로의 3분 딥러닝 파이토치맛 5장 스터디 (0) | 2023.12.13 |
| 펭귄브로의 3분 딥러닝 파이토치맛 7장 스터디 (0) | 2023.12.13 |
| 밑바닥부터 시작하는 딥러닝 7장 스터디 (0) | 2023.12.13 |



