펭귄브로의 3분 딥러닝 파이토치맛 5장 스터디
※ 본 포스팅은 펭귄브로의 3분 딥러닝 파이토치맛에 기재된 내용과 사진을 기반으로 포스팅하였습니다.

예제 소스 : https://github.com/keon/3-min-pytorch
GitHub - keon/3-min-pytorch: <펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드
<펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드. Contribute to keon/3-min-pytorch development by creating an account on GitHub.
github.com
5장은 영상 처리에 탁월한 성능을 자랑하는 CNN에 대한 내용이다.
- CNN 기초
- CNN 모델 구현하기
- ResNet으로 컬러 데이터셋에 적용하기
1960년대에 신경과학자인 데이비드 휴벨과 토르스텐 비젤은 시각을 담당하는 신경세포를 연구했다. 간단한 모양의 이미지를 보여주고 뇌가 어떻게 반응하는지 살피는 실험으로 결과는 서로 비슷한 이미지들은 고양이 뇌의 특정 부위를 지속적으로 자극하며, 서로 다른 이미지는 다른 부위를 자극한다는 사실을 발견했다.

결과적으로 이미지의 각 부분에 뇌의 서로 다른 부분이 반응하여 전체 이미지를 인식한다는 결론을 낳았다. 이 현상에 영감을 받아 만든 신경망 모델이 바로 컨볼루션 신경망이다. 합성곱 신경망(convolution neural network, CNN)이라고도 한다.
CNN은 이미지나 비디오 같은 영상 인식에 특화된 설계로, 병렬 처리가 쉬워서 대규모 서비스에 적용할 수 있다.
5.1 CNN 기초
컴퓨터에서 모든 이미지는 픽셀 값들을 가로, 세로로 늘어놓은 행렬로 표현할 수 있다.
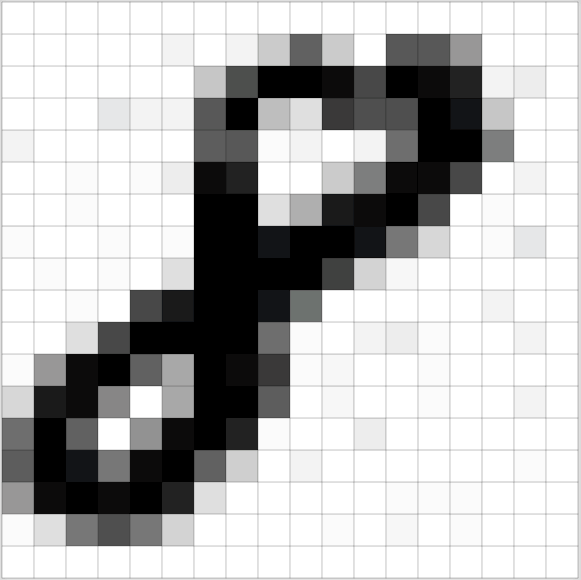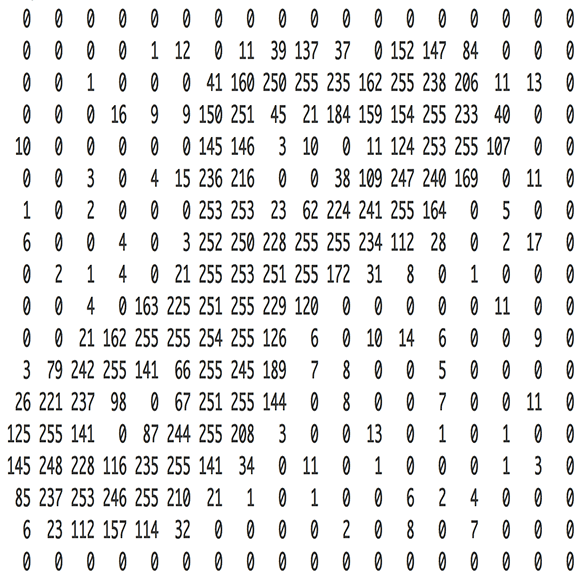
색깔이 칠해져 있는 모습이 우리가 보는 이미지이고, 숫자로 이루어진 모습이 컴퓨터가 보는 이미지이다.
일반적인 인공 신경망은 다양한 형태의 입력에 대한 확장성이 떨어진다. 그래서 이미지가 옆으로 조금만 치우쳐져도 예측률이 급격하게 떨어진다. 특징을 추출하는 가중치가 가운데만 집중하도록 학습되었기 때문이다.

5.1.2 컨볼루션
사람은 이미지를 보는 순간 이미지 속의 계층적인 특성을 곧바로 인식한다. 무의식적으로 이미지 속의 점과 선 등의 특징을 보고 얼굴 이미지를 볼 때 눈, 코, 입을 인식하고, 이 특징들을 모아 그 대상이 얼굴임을 인식하게 되는 식이다.
컨볼루션의 목적은 이처럼 계층적으로 인식할 수 있도록 단계마다 이미지의 특징을 추출하는 것이다.
이미지에 다양한 필터를 적용하여 윤곽선, 질감, 털 등 각종 특징을 추출할 수 있다.
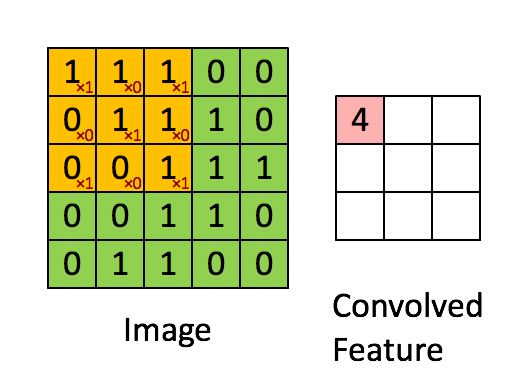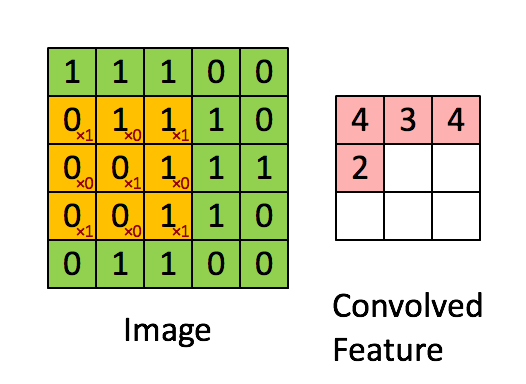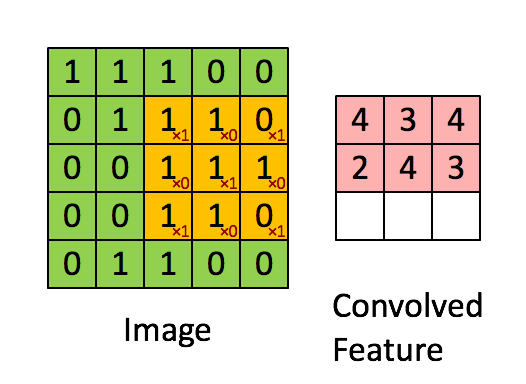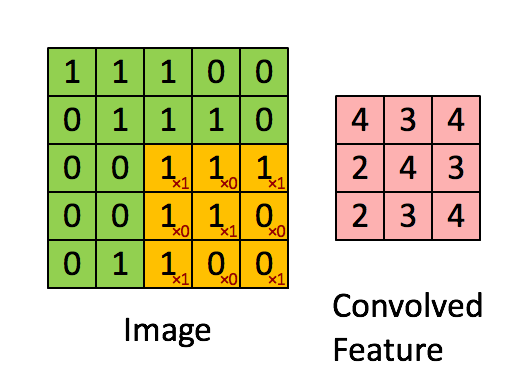
필터를 적용할 때 이미지 왼쪽 위에서 오른쪽 밑까지 밀어가며 곱하고 더하는데, 이 작업을 '컨볼루션'이라고 한다.
CNN은 이미지를 추출하는 필터를 학습한다. 이 필터가 하나의 작은 신경망이다.
5.1.3 CNN 모델
CNN 모델은 일반적으로 컨볼루션 계층, 풀링 계층, 특징들을 모아 최종 분류하는 일반적인 인공 신경망 계층으로 구성된다.
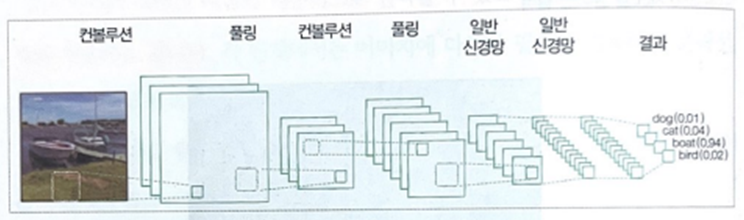
컨볼루션 계층은 이미지의 특징을 추출하는 역할을 하며, 풀링 계층은 필터를 거친 여러 특징 중 가장 중요한 특징 하나를 골라낸다. 풀링 계층은 덜 중요한 특징을 버리기 때문에 이미지의 차원이 감소한다. 또한, 특징을 값 하나로 추려내서 특징 맵의 크기를 줄여주고 중요한 특징을 강조하는 역할을 한다. 필터가 지나갈 때마다 픽셀을 묶어서 평균이나 최댓값을 가져오는 간단한 연산으로 이뤄진다.
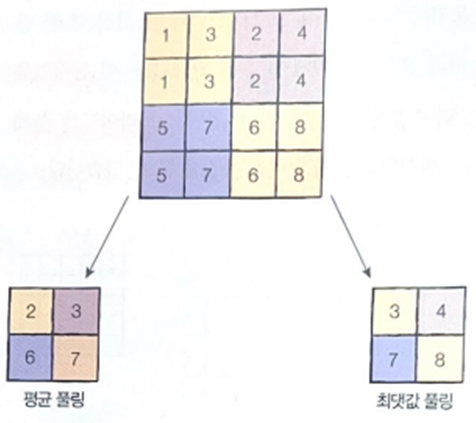
신경망은 모든 조각에 동일하게 적용되며, 특징을 추출하기 때문에 컨볼루션 필터 혹은 커널이라고도 하며, 커널은 컨볼루션 계층 하나에 여러 개가 존재할 수 있다. 보통 3 X 3, 5 X 5 크기의 커널이 쓰인다. 학습 시 필터 행렬의 값은 특징을 잘 뽑을 수 있도록 최적화된다.
컨볼루션은 움직일 때 한 칸씩 움직일 수도 있고, 여러 칸을 건너뛰게 할 수도 있다. 이 움직임을 조절하는 값을 스트라이드라고 한다. 스트라이드를 크게 하면 출력되는 텐서의 크기가 작아지는 것을 알 수 있다.
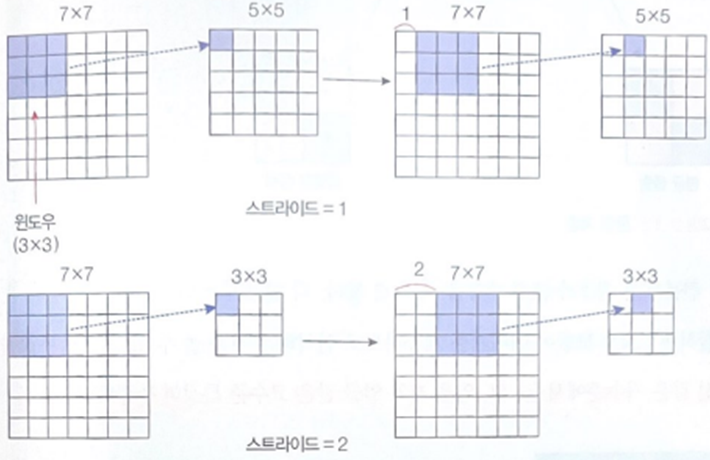
컨볼루션을 거쳐 만들어진 새로운 이미지는 특징 맵이라고 부르며, 특징 맵의 크기가 크면 학습이 어렵고 과적합의 위험이 증가한다.
특징이 선 같은 저수준에서 눈, 코, 입을 거쳐 얼굴 같은 고수준 특징이 추출되는 것이다.

CNN은 사물이 조금만 치우쳐도 인식하지 못하던 인공 신경망의 문제를 이미지 전체에 필터를 적용해 특징을 추출하는 방식으로 해결해줍니다.

5.3.1 ResNet , 5.3.3 CNN을 깊게 쌓는 방법
데이터셋이 복잡해질수록 깊게 쌓아 올린 인공 신경망이 더 유리할 수 있다. 하지만 미분을 하면서 생기는 gradient vanishing과 gradient exploding 문제 등으로 모델의 층이 너무 깊으면 성능이 떨어질 수 있다. 또한, 여러 단계의 신경망을 거치며 최초 입력 이미지에 대한 정보가 소실되는 문제도 발생한다.

train data, test data의 error가 층이 낮을수록 덜 나는 결과가 나온 것을 그래프로 확인할 수 있다. ResNet이라는 모델은 신경망을 깊게 쌓으면 오히려 성능이 나빠지는 문제를 해결하는 방법을 제시했다. 컨볼루션의 출력에 전의 전 계층에 쓰였던 입력을 더함(⊕)으로써 특징이 유실되지 않도록 합니다.

기울기 소실 문제가 해결되어 신경망의 층을 깊게 할 수 있다.

신경망의 층을 깊게 했어도 error 적게 나왔다는 것을 오른쪽 그래프를 보면 알 수 있다.
ResNet의 핵심은 네트워크를 작은 블록인 Residual 블록으로 나누었다는 것이다. Residual 블록의 출력에 입력이었던 x를 더함으로써 모델을 훨씬 깊게 설계할 수 있도록 했다. 입력과 출력의 관계를 바로 학습하기보다 입력과 출력의 차이를 따로 학습하는 게 성능이 좋다는 가설이다.
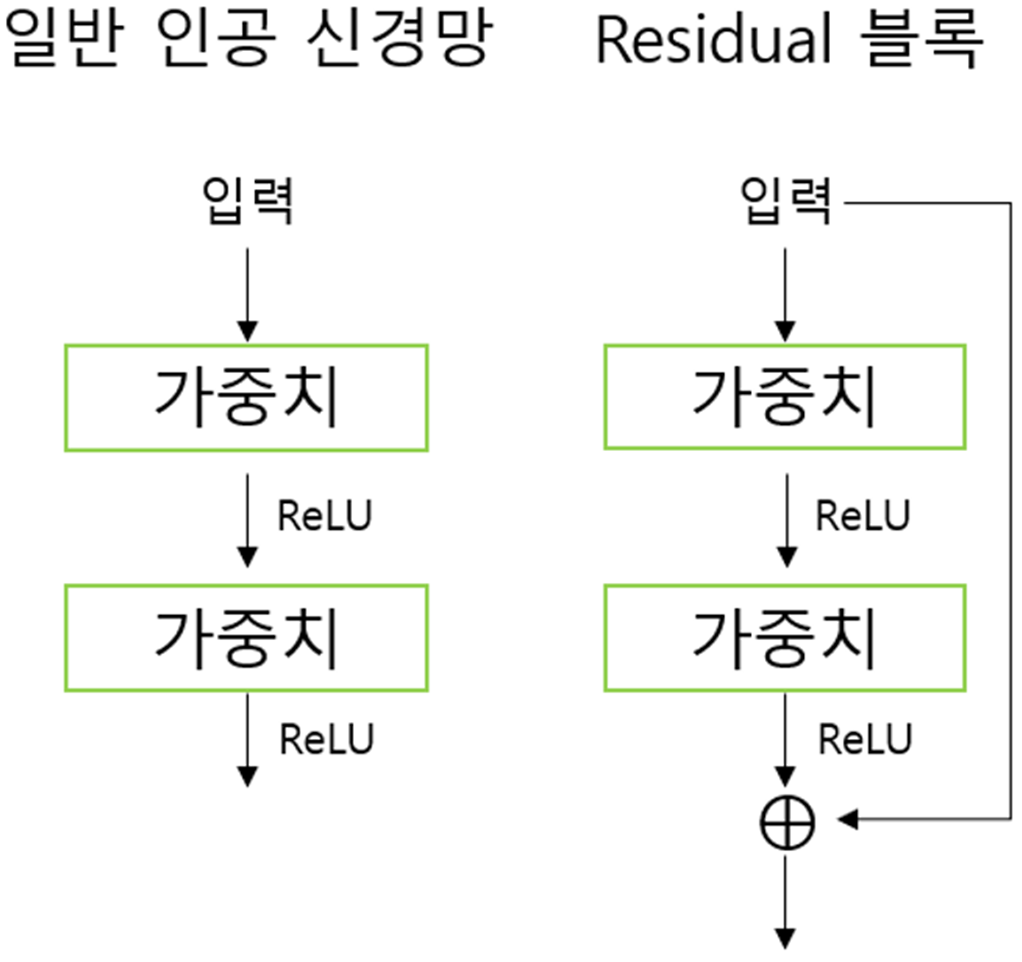
신경망을 깊게 할 수록 좋은 이유는 문제를 더 작은 단위로 분해하여 학습 효율이 좋아지기 때문이다. ResNet은 층이 많아 복잡한 모델로 보일 수 있지만 Residual 블록을 반복적으로 쌓은 것일 뿐이다.
5.3.2. CIFAR-10 데이터셋
ResNet모델에서는 CIFAR-10 데이터셋을 사용하겠다. CIFAR-10 데이터셋은 32 X 32 크기의 이미지 6만 개를 포함하고 있으며 자동차, 새, 고양이, 사슴 등 10가지 분류가 존재한다. 이때, CIFAR-10에서 10이 의미하는 바가 바로 레이블(분류)의 개수이다. 그리고 CIFAR-10 데이터셋은 컬러 이미지들을 포함하고 있다. 컬러 이미지의 픽셀 값은 몇 가지 채널들로 구성된다.
채널이란, 이미지의 색상 구성요소를 가리키며 빨강(R), 초록(G), 파랑(B) 세 종류의 광원을 혼합하여 모든 색을 표현한다.
만약 컬러 이미지라면 RGB 색생값을 고려해서 차원을 늘려야 한다. 그렇게 되면 이미지 한 개의 입력 크기가 32 X 32 X 2 = 3,072개가 된다. PNG와 같은 형식의 이미지들은 투명도까지 4종류의 채널을 가진다.

배치 정규화란 학습률을 너무 높게 잡으면 기울기가 소실되거나 발산하는 증상을 예방하여 학습 과정을 안정화하는 방법이다. 즉, 학습 중 각 계층에 들어가는 입력을 평균과 분산으로 정규화함으로써 학습을 효율적으로 만들어준다. 이 계층은 자체적으로 정규화를 수행해 드롭아웃과 같은 효과(오버피팅 예방)를 내는 장점이 있다. 배치 정규화는 신경망 내부 데이터에 직접 영향을 주는 방식이다.

학습의 효율을 높이기 위해 학습률 감소(learning rate decay)기법을 사용한다. 학습률 감소는 학습이 진행하면서 최적화 함수의 학습률을 점점 낮춰서 더 정교하게 최적화한다.

scheduler는 에폭마다 호출되며 step_size를 50으로 지정해주어 50번 호출될 때 학습률에 0.1(gamma값)을 곱한다. 0.1로 시작한 학습률은 50 에폭 후에 0.01로 낮아진다.
5.4 마치며
컴퓨터가 인식하는 이미지에 대해 좀 더 고찰해보고 컨볼루션 신경망의 구성 부분들인 컨볼루션, 커널, 풀링 등에 관해 알아보았습니다.